04_Mybatis源码-核心包
一、源码阅读
主要阅读jdbc包、cache包、transaction包、cursor包、executor包、session包、plugin包
1.1 jdbc包
jdbc包提供了数据库操作语言的执行和脚本运行的能力,这个包是一个独立的包,其他地方都没有使用是提供出来方便我们使用的,可以用来初始化sql脚本、执行建表语句等。有两个类弃用了,之后就只有6个类。可以分为sql语句生成(AbstractSQL、SQL)、脚本执行(ScriptRunner)、sql执行(SqlRunner)、其他(RuntimeSqlException、Null)
1.1.1 sql语句生成
主要是拼接sql语句(insert、delet、update、select)。提供了一个AbstractSQL抽象类,里面全部是大写的方法为了在调用的时候看着像sql语句一样,后面如果需要扩展sql功能也可以自己实现AbstractSQL类。SQL类只是继承了AbstractSQL并返回了自己。
// 使用方式
@Test
void shouldDemonstrateFluentStyle() {
//Fluent Style
final String sql = new SQL()
.SELECT("id, name").FROM("PERSON A")
.WHERE("name like ?")
.WHERE("id = ?").toString();
assertEquals("" +
"SELECT id, name\n" +
"FROM PERSON A\n" +
"WHERE (name like ? AND id = ?)", sql);
}
// 拼接逻辑 将sql拼接为为一串sql
private String selectSQL(SafeAppendable builder) {
if (distinct) {
sqlClause(builder, "SELECT DISTINCT", select, "", "", ", ");
} else {
sqlClause(builder, "SELECT", select, "", "", ", ");
}
sqlClause(builder, "FROM", tables, "", "", ", ");
// join处理
joins(builder);
sqlClause(builder, "WHERE", where, "(", ")", " AND ");
sqlClause(builder, "GROUP BY", groupBy, "", "", ", ");
sqlClause(builder, "HAVING", having, "(", ")", " AND ");
sqlClause(builder, "ORDER BY", orderBy, "", "", ", ");
limitingRowsStrategy.appendClause(builder, offset, limit);
return builder.toString();
}
1.1.2 脚本执行
脚本执行功能只有一个类主要是为了去执行sql脚本文件,提供了全文和逐行执行两种方式
// 使用方式
@Test
void shouldReturnWarningIfEndOfLineTerminatorNotFound() throws Exception {
// 创建非池化连接
DataSource ds = createUnpooledDataSource(JPETSTORE_PROPERTIES);
String resource = "org/apache/ibatis/jdbc/ScriptMissingEOLTerminator.sql";
try (Connection conn = ds.getConnection();
Reader reader = Resources.getResourceAsReader(resource)) {
// 封装数据
ScriptRunner runner = new ScriptRunner(conn);
runner.setAutoCommit(true);
runner.setStopOnError(false);
runner.setErrorLogWriter(null);
runner.setLogWriter(null);
try {
// 运行脚本
runner.runScript(reader);
fail("Expected script runner to fail due to missing end of line terminator.");
} catch (Exception e) {
assertTrue(e.getMessage().contains("end-of-line terminator"));
}
}
}
// 运行脚本部分逻辑
public void runScript(Reader reader) {
setAutoCommit();
try {
if (sendFullScript) {
// 全文执行
executeFullScript(reader);
} else {
// 逐行执行
executeLineByLine(reader);
}
} finally {
rollbackConnection();
}
}
1.1.3 sql执行
sql执行也只有一个类,提供了增删改查的方法,并且将处理结果进行了处理
// 使用方式
@Test
void shouldSelectOne() throws Exception {
// 创建数据源
DataSource ds = createUnpooledDataSource(JPETSTORE_PROPERTIES);
// 创建数据
runScript(ds, JPETSTORE_DDL);
runScript(ds, JPETSTORE_DATA);
try (Connection connection = ds.getConnection()) {
// 创建sqlRunner
SqlRunner exec = new SqlRunner(connection);
// 执行sql获取结果
Map<String, Object> row = exec.selectOne("SELECT * FROM PRODUCT WHERE PRODUCTID = ?", "FI-SW-01");
assertEquals("FI-SW-01", row.get("PRODUCTID"));
}
}
// 调用逻辑比较简单,下面是结果处理逻辑
private List<Map<String, Object>> getResults(ResultSet rs) throws SQLException {
List<Map<String, Object>> list = new ArrayList<>();
// 返回名称的字段名列表
List<String> columns = new ArrayList<>();
// 返回类型的处理器列表
List<TypeHandler<?>> typeHandlers = new ArrayList<>();
// 获取返回结果的表、字段信息
ResultSetMetaData rsmd = rs.getMetaData();
for (int i = 0, n = rsmd.getColumnCount(); i < n; i++) {
// 记录字段名
columns.add(rsmd.getColumnLabel(i + 1));
// 记录字段的对应类型处理器
try {
Class<?> type = Resources.classForName(rsmd.getColumnClassName(i + 1));
TypeHandler<?> typeHandler = typeHandlerRegistry.getTypeHandler(type);
if (typeHandler == null) {
typeHandler = typeHandlerRegistry.getTypeHandler(Object.class);
}
typeHandlers.add(typeHandler);
} catch (Exception e) {
// 默认的类型处理器是object处理器
typeHandlers.add(typeHandlerRegistry.getTypeHandler(Object.class));
}
}
// 循环处理结果
while (rs.next()) {
Map<String, Object> row = new HashMap<>();
for (int i = 0, n = columns.size(); i < n; i++) {
String name = columns.get(i);
TypeHandler<?> handler = typeHandlers.get(i);
// 放入结果
row.put(name.toUpperCase(Locale.ENGLISH), handler.getResult(rs, name));
}
list.add(row);
}
return list;
}
1.1.4 其他
之后就只有Null和RuntimeSqlException两个类,Null类是个枚举类主要是参数处理器类型和jdbc类型的关联,RuntimeSqlException继承了运行时异常
1.2 cache包
缓存包分为缓存key和缓存实现,缓存实现的时候为了能动态组合分为核心缓存(永久缓存、日志缓存、阻塞缓存、序列化缓存、同步缓存、事务缓存)和清理缓存(先进先出、近期最少使用、定时清理、软引用清理、弱引用清理),之后用装饰模式去组装缓存,接口如下:
public interface Cache {
// 获取标识符
String getId();
// 添加缓存
void putObject(Object key, Object value);
// 获取缓存
Object getObject(Object key);
// 删除缓存
Object removeObject(Object key);
// 清理
void clear();
// 获取数量
int getSize();
// 获取读写锁
default ReadWriteLock getReadWriteLock() {
return null;
}
}
1.2.1 缓存key
缓存key的作用是为了保证缓存的key无碰撞、比较和生成的速度快设计的类。该类利用了数据列表、数据列表个数、求和校验值、hashcode,在判断key是否相等时先通过判断hashcode、求和校验值和数据列表总数,如果其中一个不想等则说明数据不等,这几个计算是很快的。之后就是遍历数据列表进行值的判断,这个是最耗时的地方,但是确保证了不会出现碰撞的问题。源码如下:
public class CacheKey implements Cloneable, Serializable {
private static final int DEFAULT_MULTIPLIER = 37;
private static final int DEFAULT_HASHCODE = 17;
// 乘数用来计算hashcode使用
private final int multiplier;
// 如果两个类的hashcode相同,那么两个类的CacheKey一定不同
private int hashcode;
// 求和校验值,如果两个对象的该值不同那么两个类的CacheKey一定不同
private long checksum;
// 更新次数
private int count;
// 更新数据列表
private List<Object> updateList;
public CacheKey() {
this.hashcode = DEFAULT_HASHCODE;
this.multiplier = DEFAULT_MULTIPLIER;
this.count = 0;
this.updateList = new ArrayList<>();
}
// 更新缓存key
public void update(Object object) {
int baseHashCode = object == null ? 1 : ArrayUtil.hashCode(object);
count++;
// checksum = checksum + 基础hashcode
checksum += baseHashCode;
baseHashCode *= count;
// hashcode = 乘数 * hashcode + 基础hashcode
hashcode = multiplier * hashcode + baseHashCode;
updateList.add(object);
}
// 判断对象是否相等
@Override
public boolean equals(Object object) {
// 地址一样则肯定是一个对象
if (this == object) {
return true;
}
// 如果不是cacheKey对象则肯定不相等
if (!(object instanceof CacheKey)) {
return false;
}
// hashcode、checksum、count其中任何一个不相等则不相等。实现快速比较
final CacheKey cacheKey = (CacheKey) object;
if (hashcode != cacheKey.hashcode) {
return false;
}
if (checksum != cacheKey.checksum) {
return false;
}
if (count != cacheKey.count) {
return false;
}
// 遍历比较更新数据。如果其中一个不相等则不等。确保不会发生碰撞
for (int i = 0; i < updateList.size(); i++) {
Object thisObject = updateList.get(i);
Object thatObject = cacheKey.updateList.get(i);
if (!ArrayUtil.equals(thisObject, thatObject)) {
return false;
}
}
return true;
}
@Override
public CacheKey clone() throws CloneNotSupportedException {
CacheKey clonedCacheKey = (CacheKey) super.clone();
clonedCacheKey.updateList = new ArrayList<>(updateList);
return clonedCacheKey;
}
// ...
}
1.2.2 核心缓存
1.2.2.1 永久缓存PerpetualCache
主要有两个属性,一个是唯一标识一个是用来存储数据的map。逻辑不复杂源码如下:
public class PerpetualCache implements Cache {
// 标识唯一一个缓存,一般用命名空间
private final String id;
// 存储数据
private final Map<Object, Object> cache = new HashMap<>();
@Override
public void putObject(Object key, Object value) {
cache.put(key, value);
}
}
1.2.2.2 阻塞缓存BlockingCache
主要是为了实现一个线程在请求数据库的时候,另一个线程也用同样的参数去请求。这个时候后面的线程应该等待第一个线程查询完成之后获取第一个线程的查询结果。3.5.7版本是用的CountDownLatch实现的锁等待功能,之前的的版本是用的ReentrantLock实现的。具体源码如下:
// 阻塞缓存:实现如果第一个请求数据库还没有得到数据,第二个请求是相同的情况数据
// 那么第二个请求就阻塞等待第一个查询到数据后直接返回给第二个请求
public class BlockingCache implements Cache {
// 锁等待时间
private long timeout;
// 被装饰对象
private final Cache delegate;
// 锁的映射表,键为缓存的key,值为锁
private final ConcurrentHashMap<Object, CountDownLatch> locks;
@Override
public void putObject(Object key, Object value) {
try {
// 向缓存中放入数据
delegate.putObject(key, value);
} finally {
// 释放锁
releaseLock(key);
}
}
@Override
public Object getObject(Object key) {
// 获取锁
acquireLock(key);
// 读取结果
Object value = delegate.getObject(key);
// 结果为null释放锁
if (value != null) {
releaseLock(key);
}
// 如果没有读到值,则不会释放锁。等到读到数据库数据之后调用put方法后释放锁
return value;
}
// 获取某个键的锁
private void acquireLock(Object key) {
// CountDownLatch能够使一个线程在等待另外一些线程完成各自工作之后,再继续执行
CountDownLatch newLatch = new CountDownLatch(1);
while (true) {
// 如果传入key对应的value已经存在,就返回存在的value,不进行替换。如果不存在,就添加key和value,返回null
CountDownLatch latch = locks.putIfAbsent(key, newLatch);
if (latch == null) {
break;
}
try {
if (timeout > 0) {
// 使当前线程在锁存器倒计数至零之前一直等待,除非线程被中断或超出了指定的等待时间。如果当前计数为零,则此方法立刻返回true值
boolean acquired = latch.await(timeout, TimeUnit.MILLISECONDS);
if (!acquired) {
throw new CacheException(
"Couldn't get a lock in " + timeout + " for the key " + key + " at the cache " + delegate.getId());
}
} else {
// 阻塞当前线程,直到计数器的值为0
latch.await();
}
} catch (InterruptedException e) {
throw new CacheException("Got interrupted while trying to acquire lock for key " + key, e);
}
}
}
// 释放锁
private void releaseLock(Object key) {
CountDownLatch latch = locks.remove(key);
if (latch == null) {
throw new IllegalStateException("Detected an attempt at releasing unacquired lock. This should never happen.");
}
// 递减锁存器的计数,如果计数到达零,则释放所有等待的线程
latch.countDown();
}
// ...
}
1.2.2.3 日志缓存LoggingCache
主要是为了记录缓存的命中次数和请求次数
// 记录缓存的命中次数和请求次数
public class LoggingCache implements Cache {
private final Log log;
private final Cache delegate;
// 请求次数
protected int requests = 0;
protected int hits = 0;
public LoggingCache(Cache delegate) {
this.delegate = delegate;
this.log = LogFactory.getLog(getId());
}
@Override
public String getId() {
return delegate.getId();
}
@Override
public int getSize() {
return delegate.getSize();
}
@Override
public void putObject(Object key, Object object) {
delegate.putObject(key, object);
}
@Override
public Object getObject(Object key) {
requests++;
final Object value = delegate.getObject(key);
if (value != null) {
hits++;
}
if (log.isDebugEnabled()) {
log.debug("Cache Hit Ratio [" + getId() + "]: " + getHitRatio());
}
return value;
}
// ...
}
1.2.2.4 定时缓存ScheduledCache
主要是通过设置时间间隔之后通过间隔时间清理缓存,在get/put时进行清理操作。清理逻辑不是定时去清理,而是通过get/put时去判断清理这样减少了一个清理的定时任务。
public class ScheduledCache implements Cache {
// 被装饰缓存
private final Cache delegate;
// 清理的时间间隔
protected long clearInterval;
// 上次清理时刻
protected long lastClear;
public ScheduledCache(Cache delegate) {
this.delegate = delegate;
this.clearInterval = TimeUnit.HOURS.toMillis(1);
this.lastClear = System.currentTimeMillis();
}
@Override
public Object removeObject(Object key) {
// 非实时的去进行调用清理
clearWhenStale();
return delegate.removeObject(key);
}
// 根据时间间隔设置缓存清理(第一次缓存上后,只能第二次调用的时候如果时间超出类时间间隔才会clear)
private boolean clearWhenStale() {
if (System.currentTimeMillis() - lastClear > clearInterval) {
clear();
return true;
}
return false;
}
// ...
}
1.2.2.5 序列化缓存SerializedCache
主要是对数据进行序列化存储和反序列化,为了实现每次读取的都是一个全新的对象而不是一个对象的引用。如果是对象的引用可能调用方在获取对象后进行对象的操作就会修改对象里面的值,而我们希望缓存里面的数据不变。这个时候就可以用SerializedCache,新的对象不影响缓存中的对象。
public class SerializedCache implements Cache {
private final Cache delegate;
public SerializedCache(Cache delegate) {
this.delegate = delegate;
}
@Override
public void putObject(Object key, Object object) {
// 数据必须可序列化
if (object == null || object instanceof Serializable) {
// 数据序列化后存储缓存
delegate.putObject(key, serialize((Serializable) object));
} else {
throw new CacheException("SharedCache failed to make a copy of a non-serializable object: " + object);
}
}
@Override
public Object getObject(Object key) {
Object object = delegate.getObject(key);
// 数据反序列化
return object == null ? null : deserialize((byte[]) object);
}
// 序列化
private byte[] serialize(Serializable value) {
try (ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos)) {
oos.writeObject(value);
oos.flush();
return bos.toByteArray();
} catch (Exception e) {
throw new CacheException("Error serializing object. Cause: " + e, e);
}
}
// 反序列化
private Serializable deserialize(byte[] value) {
SerialFilterChecker.check();
Serializable result;
try (ByteArrayInputStream bis = new ByteArrayInputStream(value);
ObjectInputStream ois = new CustomObjectInputStream(bis)) {
result = (Serializable) ois.readObject();
} catch (Exception e) {
throw new CacheException("Error deserializing object. Cause: " + e, e);
}
return result;
}
public static class CustomObjectInputStream extends ObjectInputStream {
public CustomObjectInputStream(InputStream in) throws IOException {
super(in);
}
@Override
protected Class<?> resolveClass(ObjectStreamClass desc) throws ClassNotFoundException {
return Resources.classForName(desc.getName());
}
}
// ...
}
1.2.2.6 同步缓存SynchronizedCache
这个缓存就是在getSize、putObject、getObject、removeObject、clear方法上面添加了synchronized后调用被装饰对象
1.2.2.7 事务缓存TransactionalCache
事务缓存提供了事务提交时存入缓存,事务回滚时销毁缓存的功能。之后还提供了一个事务缓存管理器用来管理事务缓存进行多个事务的存入或销毁操作。
// 提供了事务提交时存入缓存,事务回滚时销毁缓存的功能
public class TransactionalCache implements Cache {
private static final Log log = LogFactory.getLog(TransactionalCache.class);
// 被装饰的对象
private final Cache delegate;
// 事务提交后是否直接清理缓存
private boolean clearOnCommit;
// 事务提交时候需要写入缓存的数据
private final Map<Object, Object> entriesToAddOnCommit;
// 缓存查询未命中的数据(为什么要保存未命中的数据:缓存可能被blockingCache装饰过,
// 如果数据的结果查询为空,则会对数据进行上锁从而阻塞后面的查询,这个数据就是为了后期解锁用的)
private final Set<Object> entriesMissedInCache;
public TransactionalCache(Cache delegate) {
this.delegate = delegate;
this.clearOnCommit = false;
this.entriesToAddOnCommit = new HashMap<>();
this.entriesMissedInCache = new HashSet<>();
}
@Override
public Object getObject(Object key) {
// issue #116 从缓存中读取数据
Object object = delegate.getObject(key);
// 未命中缓存记录到set中
if (object == null) {
entriesMissedInCache.add(key);
}
// issue #146 如果设置了提交时立即清理则返回空
if (clearOnCommit) {
return null;
} else {
// 返回查询结果
return object;
}
}
@Override
public void putObject(Object key, Object object) {
// 先将数据放到 需要写入缓存 的列表中
entriesToAddOnCommit.put(key, object);
}
public void commit() {
// 是直接清理缓存,则直接清理缓存
if (clearOnCommit) {
delegate.clear();
}
// 将未写入缓存的数据写入缓存
flushPendingEntries();
// 清理环境
reset();
}
public void rollback() {
// 删除缓存未命中的数据
unlockMissedEntries();
// 清理数据
reset();
}
// 清理环境
private void reset() {
clearOnCommit = false;
entriesToAddOnCommit.clear();
entriesMissedInCache.clear();
}
// 刷新到缓存里面将未写入缓存的数据
private void flushPendingEntries() {
// 将entriesToAddOnCommit里面的数据写入缓存
for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) {
delegate.putObject(entry.getKey(), entry.getValue());
}
// 将entriesMissedInCache里面的数据写入缓存
for (Object entry : entriesMissedInCache) {
if (!entriesToAddOnCommit.containsKey(entry)) {
delegate.putObject(entry, null);
}
}
}
// 删除未命中的数据
private void unlockMissedEntries() {
for (Object entry : entriesMissedInCache) {
try {
delegate.removeObject(entry);
} catch (Exception e) {
log.warn("Unexpected exception while notifying a rollback to the cache adapter. "
+ "Consider upgrading your cache adapter to the latest version. Cause: " + e);
}
}
}
// ...
}
事务管理器
// 用来管理一个事务中的多个缓存
public class TransactionalCacheManager {
// 管理多个缓存的映射
private final Map<Cache, TransactionalCache> transactionalCaches = new HashMap<>();
// 事务提交
public void commit() {
for (TransactionalCache txCache : transactionalCaches.values()) {
txCache.commit();
}
}
// 事务回滚
public void rollback() {
for (TransactionalCache txCache : transactionalCaches.values()) {
txCache.rollback();
}
}
private TransactionalCache getTransactionalCache(Cache cache) {
return MapUtil.computeIfAbsent(transactionalCaches, cache, TransactionalCache::new);
}
// ...
}
1.2.3 清理缓存
1.2.3.1 先进先出FifoCache
通过添加一个缓存数量和缓存队列的字段去实现先进先出的功能,如果缓存数量超过了缓存的数量就将最先进入的缓存删除掉
// 先进先出策略清理
public class FifoCache implements Cache {
// 被装饰对象
private final Cache delegate;
// 队列保存缓存key
private final Deque<Object> keyList;
// 缓存空间大写
private int size;
public FifoCache(Cache delegate) {
this.delegate = delegate;
this.keyList = new LinkedList<>();
this.size = 1024;
}
@Override
public void putObject(Object key, Object value) {
cycleKeyList(key);
delegate.putObject(key, value);
}
private void cycleKeyList(Object key) {
keyList.addLast(key);
// 如果超过缓存数量则删除缓存
if (keyList.size() > size) {
Object oldestKey = keyList.removeFirst();
delegate.removeObject(oldestKey);
}
}
// ...
}
1.2.3.2 近期最少使用LruCache
近期最少使用功能主要是利用的LinkedHashMap的记录顺序特性实现的功能,记录了调用get方法的次数。然后删除最少使用的缓存
// 近期最少使用清理
public class LruCache implements Cache {
private final Cache delegate;
// 保存的缓存数据的键
private Map<Object, Object> keyMap;
// 最近最少使用的键
private Object eldestKey;
public LruCache(Cache delegate) {
this.delegate = delegate;
setSize(1024);
}
public void setSize(final int size) {
// 注意LinkedHashMap的第三个参数,true表示该LinkedHashMap记录的顺序access-order
// 也就是说调用LinkedHashMap的get方法会改变其记录的顺序
keyMap = new LinkedHashMap<Object, Object>(size, .75F, true) {
private static final long serialVersionUID = 4267176411845948333L;
/**
* 每次LinkedHashMap放入数据时触发
* @param eldest 最久没有被使用的数据
* @return 最久没有被使用的数据是否应该被删除
*/
@Override
protected boolean removeEldestEntry(Map.Entry<Object, Object> eldest) {
boolean tooBig = size() > size;
if (tooBig) {
// 设置最少使用的key
eldestKey = eldest.getKey();
}
return tooBig;
}
};
}
@Override
public void putObject(Object key, Object value) {
delegate.putObject(key, value);
// 向keyMap中存放key,并删除使用最久的key
cycleKeyList(key);
}
@Override
public Object getObject(Object key) {
// 触发一下当前被访问的键
keyMap.get(key); // touch
return delegate.getObject(key);
}
private void cycleKeyList(Object key) {
keyMap.put(key, key);
// 如果最少使用的键不为空则直接删除
if (eldestKey != null) {
delegate.removeObject(eldestKey);
eldestKey = null;
}
}
}
1.3.3.3 弱引用WeakCache
主要是利用的jvm的弱引用清理实现的,在jvm清理缓存之后去删除对应的缓存key
// 将缓存包装为弱引用,便于jvm清理
public class WeakCache implements Cache {
// 强引用对象列表
private final Deque<Object> hardLinksToAvoidGarbageCollection;
// 弱引用对象列表
private final ReferenceQueue<Object> queueOfGarbageCollectedEntries;
// 被装饰对象
private final Cache delegate;
// 强引用对象的限制
private int numberOfHardLinks;
public WeakCache(Cache delegate) {
this.delegate = delegate;
this.numberOfHardLinks = 256;
this.hardLinksToAvoidGarbageCollection = new LinkedList<>();
this.queueOfGarbageCollectedEntries = new ReferenceQueue<>();
}
@Override
public void putObject(Object key, Object value) {
// 删除垃圾回收队列中的元素
removeGarbageCollectedItems();
// 将弱引用put到被装饰对象中
delegate.putObject(key, new WeakEntry(key, value, queueOfGarbageCollectedEntries));
}
@Override
public Object getObject(Object key) {
Object result = null;
@SuppressWarnings("unchecked") // assumed delegate cache is totally managed by this cache
// 从缓存中查找对应的缓存项
WeakReference<Object> weakReference = (WeakReference<Object>) delegate.getObject(key);
// 存在缓存项
if (weakReference != null) {
result = weakReference.get();
// 已经被gc回收
if (result == null) {
// 清楚对应缓存项
delegate.removeObject(key);
} else {
synchronized (hardLinksToAvoidGarbageCollection) {
// 将value添加到hardLinksToAvoidGarbageCollection保留
hardLinksToAvoidGarbageCollection.addFirst(result);
// 如果hardLinksToAvoidGarbageCollection的数量超过强引用对象的限制
if (hardLinksToAvoidGarbageCollection.size() > numberOfHardLinks) {
// 直接删除
hardLinksToAvoidGarbageCollection.removeLast();
}
}
}
}
return result;
}
@Override
public void clear() {
synchronized (hardLinksToAvoidGarbageCollection) {
hardLinksToAvoidGarbageCollection.clear();
}
removeGarbageCollectedItems();
delegate.clear();
}
// 将已经被垃圾回收掉的对象清理掉
private void removeGarbageCollectedItems() {
WeakEntry sv;
// 取出的是软引用的包装类,遍历集合,清楚被gc过的key
// ReferenceQueue.poll方法遍历队列,如果引用不可以则获取对象并返回,否则返回null
while ((sv = (WeakEntry) queueOfGarbageCollectedEntries.poll()) != null) {
delegate.removeObject(sv.key);
}
}
private static class WeakEntry extends WeakReference<Object> {
// 这个属性不会被清理掉,存储目标对象的key
private final Object key;
private WeakEntry(Object key, Object value, ReferenceQueue<Object> garbageCollectionQueue) {
super(value, garbageCollectionQueue);
this.key = key;
}
}
// ...
}
1.3.3.4 软引用SoftCache
软引用逻辑和弱引用逻辑一致
1.3.4 缓存的组建
缓存的组建就是添加装饰的过程
// 通过mapper.xml里面的缓存配置去装饰
<cache type="PERPETUAL" eviction="FIFO" flushInterval="6000" size="512" readOnly="true" blocking="true"/>
public Cache build() {
// 设置缓存的默认实现
setDefaultImplementations();
// 创建默认的缓存
Cache cache = newBaseCacheInstance(implementation, id);
setCacheProperties(cache);
// issue #352, do not apply decorators to custom caches
// 缓存实现类是PerpetualCache
if (PerpetualCache.class.equals(cache.getClass())) {
// 遍历装饰器,逐级嵌套自定义装饰器
for (Class<? extends Cache> decorator : decorators) {
cache = newCacheDecoratorInstance(decorator, cache);
setCacheProperties(cache);
}
// 添加标准装饰器
cache = setStandardDecorators(cache);
}
// 日志缓存处理
else if (!LoggingCache.class.isAssignableFrom(cache.getClass())) {
// 添加日志装饰器
cache = new LoggingCache(cache);
}
return cache;
}
// 为缓存添加标准的装饰器
private Cache setStandardDecorators(Cache cache) {
try {
// 设置缓存大小
MetaObject metaCache = SystemMetaObject.forObject(cache);
if (size != null && metaCache.hasSetter("size")) {
metaCache.setValue("size", size);
}
// 定义了清理间隔则添加清理装饰器
if (clearInterval != null) {
cache = new ScheduledCache(cache);
((ScheduledCache) cache).setClearInterval(clearInterval);
}
// 如果允许读写则添加序列化装饰器
if (readWrite) {
cache = new SerializedCache(cache);
}
// 添加日志和同步装饰器
cache = new LoggingCache(cache);
cache = new SynchronizedCache(cache);
// 开启了阻塞功能则添加阻塞装饰器
if (blocking) {
cache = new BlockingCache(cache);
}
return cache;
} catch (Exception e) {
throw new CacheException("Error building standard cache decorators. Cause: " + e, e);
}
}
mybatis提供一级和二级缓存,在获取缓存数据的时候是先去获取二级缓存的数据,如果不存在则获取一级缓存的数据。一级缓存是默认开启的,二级缓存有4个地方需要配置。在配置之后缓存管理器(CachingExecutor)里面就会去处理缓存逻辑
<!--
二级缓存的相关配置有四项:
1. <setting name="cacheEnabled" value="true"/> 默认就是true
2. <cache/>和<cache-ref/>标签来开启和配置缓存
3. <select useCache = "true"/> 只有1、2都启用之后这个才生效,默认为true
4. <select flushCache = "true"/> 在执行语句之前是否清理一级二级缓存
开启二级缓存-->
1.3 transaction包
事务包里面的逻辑比较简单提供了2个接口(事务接口和事务工厂)并各自有2个实现(jdbc和managed)。接口源码如下:
public interface Transaction {
// 获取连接
Connection getConnection() throws SQLException;
// 事务提交
void commit() throws SQLException;
// 事务回滚
void rollback() throws SQLException;
// 事务取消
void close() throws SQLException;
// 获取超时时间
Integer getTimeout() throws SQLException;
}
public interface TransactionFactory {
/**
* Sets transaction factory custom properties.
* @param props
* the new properties
*/
// 设置属性
default void setProperties(Properties props) {
// NOP
}
// 创建事务通过数据库连接
Transaction newTransaction(Connection conn);
// 创建事务通过数据源和事务隔离级别
Transaction newTransaction(DataSource dataSource, TransactionIsolationLevel level, boolean autoCommit);
}
jdbc事务实现类如下
// jdbc事务
public class JdbcTransaction implements Transaction {
private static final Log log = LogFactory.getLog(JdbcTransaction.class);
// 数据库连接
protected Connection connection;
// 数据源
protected DataSource dataSource;
// 事务隔离级别
protected TransactionIsolationLevel level;
// 是否自动提交
protected boolean autoCommit;
public JdbcTransaction(DataSource ds, TransactionIsolationLevel desiredLevel, boolean desiredAutoCommit) {
dataSource = ds;
level = desiredLevel;
autoCommit = desiredAutoCommit;
}
public JdbcTransaction(Connection connection) {
this.connection = connection;
}
@Override
public Connection getConnection() throws SQLException {
// 连接为空则打开连接
if (connection == null) {
openConnection();
}
return connection;
}
@Override
public void commit() throws SQLException {
// 如果连接不为空与连接非自动提交则提交
if (connection != null && !connection.getAutoCommit()) {
if (log.isDebugEnabled()) {
log.debug("Committing JDBC Connection [" + connection + "]");
}
connection.commit();
}
}
@Override
public void rollback() throws SQLException {
// 如果连接不为空与连接非自动提交则回滚
if (connection != null && !connection.getAutoCommit()) {
if (log.isDebugEnabled()) {
log.debug("Rolling back JDBC Connection [" + connection + "]");
}
connection.rollback();
}
}
@Override
public void close() throws SQLException {
if (connection != null) {
// 重置自动提交
resetAutoCommit();
if (log.isDebugEnabled()) {
log.debug("Closing JDBC Connection [" + connection + "]");
}
connection.close();
}
}
protected void resetAutoCommit() {
try {
// 如果是false则重置为true
if (!connection.getAutoCommit()) {
if (log.isDebugEnabled()) {
log.debug("Resetting autocommit to true on JDBC Connection [" + connection + "]");
}
connection.setAutoCommit(true);
}
} catch (SQLException e) {
if (log.isDebugEnabled()) {
log.debug("Error resetting autocommit to true "
+ "before closing the connection. Cause: " + e);
}
}
}
protected void openConnection() throws SQLException {
if (log.isDebugEnabled()) {
log.debug("Opening JDBC Connection");
}
connection = dataSource.getConnection();
// 事务隔离级别不为空则设置事务隔离级别
if (level != null) {
connection.setTransactionIsolation(level.getLevel());
}
// 设置自动提交
setDesiredAutoCommit(autoCommit);
}
}
其他的工厂类都是new了一个事务接口的各自实现类。事务管理操作的实现类也差不多,唯一的区别是提交和回滚都没有实现方法,这些方法都交给了容器去处理。比如所有的事务操作都委托给了spring。
1.4 cursor包
游标主要的作用就是获取数据列表之后逐条读出。比如数据库查询结果有10条,则数据会查询到内存后逐条给出,使用方式:Cursor<对象>。这个包里面一共就两个类,一个游标接口一个游标默认实现类,游标接口继承了克隆和可迭代器接口默认实现类就要实现所有的方法。
// 游标 继承了迭代器(处理大量数据时使用)
public interface Cursor<T> extends Closeable, Iterable<T> {
// 是否开启
boolean isOpen();
// 是否已经完成遍历
boolean isConsumed();
// 返回当前元素的索引
int getCurrentIndex();
}
public class DefaultCursor<T> implements Cursor<T> {
// ResultSetHandler stuff
// 结果处理级
private final DefaultResultSetHandler resultSetHandler;
// 结果集对于的resultMap信息
private final ResultMap resultMap;
// 返回结果的详细信息(所有数据都查询在此处)
private final ResultSetWrapper rsw;
// 结果的起止信息
private final RowBounds rowBounds;
// 暂存结果
protected final ObjectWrapperResultHandler<T> objectWrapperResultHandler = new ObjectWrapperResultHandler<>();
// 内部迭代器
private final CursorIterator cursorIterator = new CursorIterator();
// 迭代器存在标志位
private boolean iteratorRetrieved;
// 游标状态
private CursorStatus status = CursorStatus.CREATED;
// 记录已经映射的行
private int indexWithRowBound = -1;
// 游标状态
private enum CursorStatus {
// 新创建游标,结果未消费
CREATED,
// 正在被使用,正在被消费
OPEN,sed cursor, not fully consumed.
*/
// 游标已经被关闭,结果未被全部关闭
CLOSED,
// 游标已经被关闭,结果全部关闭
CONSUMED
}
public DefaultCursor(DefaultResultSetHandler resultSetHandler, ResultMap resultMap, ResultSetWrapper rsw, RowBounds rowBounds) {
this.resultSetHandler = resultSetHandler;
this.resultMap = resultMap;
this.rsw = rsw;
this.rowBounds = rowBounds;
}
@Override
public Iterator<T> iterator() {
// 如果迭代器已经给出
if (iteratorRetrieved) {
throw new IllegalStateException("Cannot open more than one iterator on a Cursor");
}
// 如果游标已经关闭
if (isClosed()) {
throw new IllegalStateException("A Cursor is already closed.");
}
// 表面已经给出并返回
iteratorRetrieved = true;
return cursorIterator;
}
// 考虑边界限制,从数据库中获取下一个对象
protected T fetchNextUsingRowBound() {
// 从数据库结果中取出下一个对象
T result = fetchNextObjectFromDatabase();
// 不满足边界限制则一直去取
while (objectWrapperResultHandler.fetched && indexWithRowBound < rowBounds.getOffset()) {
result = fetchNextObjectFromDatabase();
}
return result;
}
// 从数据库获取下一个对象
protected T fetchNextObjectFromDatabase() {
if (isClosed()) {
return null;
}
try {
objectWrapperResultHandler.fetched = false;
status = CursorStatus.OPEN;
// 结果集没有关闭
if (!rsw.getResultSet().isClosed()) {
// 从结果集取出数据并存入resultSetHandler中
resultSetHandler.handleRowValues(rsw, resultMap, objectWrapperResultHandler, RowBounds.DEFAULT, null);
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
// 获取存入objectWrapperResultHandler的对象
T next = objectWrapperResultHandler.result;
if (objectWrapperResultHandler.fetched) {
// 更改索引
indexWithRowBound++;
}
// 没有新对象或者到达了边界
if (!objectWrapperResultHandler.fetched || getReadItemsCount() == rowBounds.getOffset() + rowBounds.getLimit()) {
// 数据消费完毕
close();
status = CursorStatus.CONSUMED;
}
// 清除对象
objectWrapperResultHandler.result = null;
return next;
}
// 简单的结果处理器
protected static class ObjectWrapperResultHandler<T> implements ResultHandler<T> {
protected T result;
protected boolean fetched;
@Override
public void handleResult(ResultContext<? extends T> context) {
// 取出上下文中的一条结果
this.result = context.getResultObject();
// 关闭结果上下文
context.stop();
fetched = true;
}
}
protected class CursorIterator implements Iterator<T> {
// 缓存下一个要返回的对象,在next操作中完成写入
T object;
/**
* Index of objects returned using next(), and as such, visible to users.
*/
// next方法中返回的对象索引
int iteratorIndex = -1;
// 判断是否还有下一个元素,如果有则写入object
@Override
public boolean hasNext() {
if (!objectWrapperResultHandler.fetched) {
object = fetchNextUsingRowBound();
}
return objectWrapperResultHandler.fetched;
}
// 返回下一个元素
@Override
public T next() {
// Fill next with object fetched from hasNext()
T next = object;
// 如果没有对象则尝试去获取一个
if (!objectWrapperResultHandler.fetched) {
next = fetchNextUsingRowBound();
}
// 清空返回next
if (objectWrapperResultHandler.fetched) {
objectWrapperResultHandler.fetched = false;
object = null;
iteratorIndex++;
return next;
}
throw new NoSuchElementException();
}
}
// ...
}
1.5 executor包
这个包是mybatis最重要的包,看了下类也是特别的多,按照里的子包分一下类keygen子包(生成自增主键)、loader子包(懒加载)、parameter子包、result子包、resultSet子包、statement子包、执行器核心类
1.5.2 keygen子包(生成自增主键)
包里面有一个接口三个实现类NoKeyGenerator不提供任何自增主键、Jdbc3KeyGenerator给提供自增主键的数据库、SelectKeyGenerator是Jdbc3KeyGenerator的增强版通过在执行语句的前面或者后面去执行语句。这三个实现类只能有一个被使用,如果同时加了selectKey和useGenerated则以selectKey生效。
<!-- 自增设置 Jdbc3KeyGenerator java对象插入后将自增ID回显给对象 -->
<insert id="getAllUserInfo" useGeneratedKeys="true" keyProperty="id">
</insert>
<insert id="selectList">
<!-- 自增设置 SelectKeyGenerator java对象插入后将自增ID回显给对象可以设置 -->
<selectKey resultType="java.lang.Integer" keyProperty="id" order="BEFORE" >//AFTER
SELECT LAST_INSERT_ID()
</selectKey>
</insert>
// key生成接口
public interface KeyGenerator {
// 数据插入前进行的操作
void processBefore(Executor executor, MappedStatement ms, Statement stmt, Object parameter);
// 数据插入后进行的操作
void processAfter(Executor executor, MappedStatement ms, Statement stmt, Object parameter);
}
具有自增组件的数据库准备的(获取数据库生成的主键值,提供主键的回写功能)Jdbc3KeyGenerator
@Override
// 执行sql前不做任何处理
public void processBefore(Executor executor, MappedStatement ms, Statement stmt, Object parameter) {
// do nothing
}
@Override
// 执行sql后
public void processAfter(Executor executor, MappedStatement ms, Statement stmt, Object parameter) {
processBatch(ms, stmt, parameter);
}
public void processBatch(MappedStatement ms, Statement stmt, Object parameter) {
// 拿到主键的属性名称
final String[] keyProperties = ms.getKeyProperties();
if (keyProperties == null || keyProperties.length == 0) {
return;
}
// java.sql.Statement.getGeneratedKeys()返回自增主键的ResultSet, 如果没有则返回空ResultSet对象
try (ResultSet rs = stmt.getGeneratedKeys()) {
// 输出结果的描述信息
final ResultSetMetaData rsmd = rs.getMetaData();
final Configuration configuration = ms.getConfiguration();
if (rsmd.getColumnCount() < keyProperties.length) {
// Error?
// 数据库获取的字段比属性的字段还要多,应该这里只是返显ID则不做处理
} else {
// 调用自方法,将主键赋值给实参数
assignKeys(configuration, rs, rsmd, keyProperties, parameter);
}
} catch (Exception e) {
throw new ExecutorException("Error getting generated key or setting result to parameter object. Cause: " + e, e);
}
}
真正的生成主键SelectKeyGenerator
// 主键sql语句的特有标记
public static final String SELECT_KEY_SUFFIX = "!selectKey";
// 是否插入前执行
private final boolean executeBefore;
// 用户生成语句的sql语句
private final MappedStatement keyStatement;
public SelectKeyGenerator(MappedStatement keyStatement, boolean executeBefore) {
this.executeBefore = executeBefore;
this.keyStatement = keyStatement;
}
/**
* 数据插入前进行的操作
* 1. 数据库存在自增主键:在执行特定sql语句后赋值主键后插入数据库会出现生成的和数据库不一致。这是建议使用Jdbc3KeyGenerator
* 2. 数据库不存在自增主键:在执行特定sql语句后赋值主键后完整插入数据库 *
*/
@Override
public void processBefore(Executor executor, MappedStatement ms, Statement stmt, Object parameter) {
if (executeBefore) {
processGeneratedKeys(executor, ms, parameter);
}
}
/**
* 数据插入后进行的操作
* 1. 数据库存在自增主键:可能出现数据库和java对象的值不一致,一般通过特定的sql语句保证一致和Jdbc3KeyGenerator回写功能类似 *
* 2. 数据库不存在自增主键:插入数据库的数据没有赋值,而java对象确赋值了。操作错误
*/
@Override
public void processAfter(Executor executor, MappedStatement ms, Statement stmt, Object parameter) {
if (!executeBefore) {
processGeneratedKeys(executor, ms, parameter);
}
}
// 执行特定的sql语句之后,将值赋给java对象
private void processGeneratedKeys(Executor executor, MappedStatement ms, Object parameter) {
try {
// 判空
if (parameter != null && keyStatement != null && keyStatement.getKeyProperties() != null) {
// 需要自增的属性
String[] keyProperties = keyStatement.getKeyProperties();
final Configuration configuration = ms.getConfiguration();
final MetaObject metaParam = configuration.newMetaObject(parameter);
// Do not close keyExecutor.
// The transaction will be closed by parent executor.
// 给key创建执行器
Executor keyExecutor = configuration.newExecutor(executor.getTransaction(), ExecutorType.SIMPLE);
// 执行sql语句得到主键值
List<Object> values = keyExecutor.query(keyStatement, parameter, RowBounds.DEFAULT, Executor.NO_RESULT_HANDLER);
// 主键必须唯一
if (values.size() == 0) {
throw new ExecutorException("SelectKey returned no data.");
} else if (values.size() > 1) {
throw new ExecutorException("SelectKey returned more than one value.");
} else {
MetaObject metaResult = configuration.newMetaObject(values.get(0));
if (keyProperties.length == 1) {
// 主键只有一个后进行赋值
if (metaResult.hasGetter(keyProperties[0])) {
// 在metaResult中用getter获取值
setValue(metaParam, keyProperties[0], metaResult.getValue(keyProperties[0]));
} else {
// no getter for the property - maybe just a single value object
// so try that
// 返回的直接就是主键本身
setValue(metaParam, keyProperties[0], values.get(0));
}
} else {
// 得到的值赋值给多个属性
handleMultipleProperties(keyProperties, metaParam, metaResult);
}
}
}
} catch (ExecutorException e) {
throw e;
} catch (Exception e) {
throw new ExecutorException("Error selecting key or setting result to parameter object. Cause: " + e, e);
}
}
1.5.2 loader子包(懒加载)
主要的功能是在关联表查询数据的时候,可以按需懒加载另外一张表里面的数据。即可以实现先获取主表里面的数据,之后在懒加载获取关联表数据,这样就可以减少关联表的冗余查询数据。实现原理就是给需要懒加载的类创建一个代理类,在调用get方法的时候就去判断属性是否是懒加载属性,如果是则调用相应的语句查询结果后赋值给属性。
使用方式:
<!-- mybatis-config.xml里面开启懒加载配置 -->
<settings>
<!-- 全局性设置懒加载。如果设为‘false',则所有相关联的都会被初始化加载。 -->
<setting name="lazyLoadingEnabled" value="true"/>
<!-- 当设置为‘true'的时候,懒加载的对象可能被任何懒属性全部加载。否则,每个属性都按需加载。 -->
<setting name="aggressiveLazyLoading" value="false"/>
<settings/>
<!-- 结果映射语句 -->
<resultMap type="userInfo" id="getUserInfo" autoMapping = "true">
<id column="id" property="id"/>
<result column="name" property="name"/>
<!-- select: 指定延迟加载需要执行的statement的id(根据id查询的statement)如果不在本文件中,需要加上namespace
property: resultMap中type指定类中的属性名
column:和select查询关联的字段(resultMap中存在的字段)
-->
<association property="userRole" javaType="userRole" autoMapping="true" select="getUserRoseByUserId" column="id">
</association>
</resultMap>
<!-- maper.xml里面的查询语句 -->
<select id="getUsers" resultMap="getUserInfo">
select * from user_info
</select>
<!-- 懒加载子句 -->
<select id="getUserRoseByUserId" resultType="userRole">
select * from user_role where user_id = #{userId}
</select>
// 测试懒加载
// 查询用户信息并返回用户信息的代理对象
List<UserInfo> users = userInfoMapper.getUsers();
for (UserInfo user : users) {
// 调用懒加载获取数据
UserRole userRole = user.getUserRole();
if(userRole != null ){
System.out.println(userRole.toString());
}
}
创建懒加载代理工厂堆栈:
// 判断条件后创建懒加载的动态对象
createResultObject:671, DefaultResultSetHandler (org.apache.ibatis.executor.resultset)
// 返回结果处理
getRowValue:427, DefaultResultSetHandler (org.apache.ibatis.executor.resultset)
handleRowValuesForSimpleResultMap:380, DefaultResultSetHandler (org.apache.ibatis.executor.resultset)
handleRowValues:349, DefaultResultSetHandler (org.apache.ibatis.executor.resultset)
handleResultSet:317, DefaultResultSetHandler (org.apache.ibatis.executor.resultset)
handleResultSets:201, DefaultResultSetHandler (org.apache.ibatis.executor.resultset)
// 语句处理
query:68, PreparedStatementHandler (org.apache.ibatis.executor.statement)
query:84, RoutingStatementHandler (org.apache.ibatis.executor.statement)
doQuery:66, SimpleExecutor (org.apache.ibatis.executor)
// 从数据库进行查询操作前的本地缓存处理
queryFromDatabase:351, BaseExecutor (org.apache.ibatis.executor)
query:174, BaseExecutor (org.apache.ibatis.executor)
// 缓存执行器查询接口
query:115, CachingExecutor (org.apache.ibatis.executor)
query:94, CachingExecutor (org.apache.ibatis.executor)
// DefaultSqlSession查询列表接口
selectList:159, DefaultSqlSession (org.apache.ibatis.session.defaults)
selectList:150, DefaultSqlSession (org.apache.ibatis.session.defaults)
selectList:145, DefaultSqlSession (org.apache.ibatis.session.defaults)
// 执行返回多条数据方法
executeForMany:162, MapperMethod (org.apache.ibatis.binding)
execute:85, MapperMethod (org.apache.ibatis.binding)
// mybatis的动态代理类实现类
invoke:154, MapperProxy$PlainMethodInvoker (org.apache.ibatis.binding)
invoke:89, MapperProxy (org.apache.ibatis.binding)
// jdk动态代理
getUsers:-1, $Proxy6 (com.sun.proxy)
// main方法调用
main:52, MybatisTest (com.gqs.mybatis.test)
懒加载的代理工厂源码如下:
public interface ProxyFactory {
// 设置实现方法,
default void setProperties(Properties properties) {
// NOP
}
// 创建一个代理对象
Object createProxy(Object target, ResultLoaderMap lazyLoader, Configuration configuration, ObjectFactory objectFactory, List<Class<?>> constructorArgTypes, List<Object> constructorArgs);
}
createProxy的实现类就是CglibProxyFactory源码
// 创建一个反序列化的代理对象
public Object createDeserializationProxy(Object target, Map<String, ResultLoaderMap.LoadPair> unloadedProperties, ObjectFactory objectFactory, List<Class<?>> constructorArgTypes, List<Object> constructorArgs) {
return EnhancedDeserializationProxyImpl.createProxy(target, unloadedProperties, objectFactory, constructorArgTypes, constructorArgs);
}
static Object crateProxy(Class<?> type, Callback callback, List<Class<?>> constructorArgTypes, List<Object> constructorArgs) {
Enhancer enhancer = new Enhancer();
enhancer.setCallback(callback);
// 创建的代理是原对象的子类
enhancer.setSuperclass(type);
try {
// 获取类中的writeReplace
type.getDeclaredMethod(WRITE_REPLACE_METHOD);
// ObjectOutputStream will call writeReplace of objects returned by writeReplace
if (LogHolder.log.isDebugEnabled()) {
LogHolder.log.debug(WRITE_REPLACE_METHOD + " method was found on bean " + type + ", make sure it returns this");
}
} catch (NoSuchMethodException e) {
// 没有找到则则设置代理类去继承WriteReplaceInterface接口
enhancer.setInterfaces(new Class[] { WriteReplaceInterface.class });
} catch (SecurityException e) {
// nothing to do here
}
Object enhanced;
if (constructorArgTypes.isEmpty()) {
enhanced = enhancer.create();
} else {
Class<?>[] typesArray = constructorArgTypes.toArray(new Class[constructorArgTypes.size()]);
Object[] valuesArray = constructorArgs.toArray(new Object[constructorArgs.size()]);
enhanced = enhancer.create(typesArray, valuesArray);
}
return enhanced;
}
创建代理类之后在代码中的get/set方法都是请求的代理类的intercept方法
private static class EnhancedResultObjectProxyImpl implements MethodInterceptor {
// 被代理类
private final Class<?> type;
// 需要懒加载的属性map
private final ResultLoaderMap lazyLoader;
// 是否是激进懒加载
private final boolean aggressive;
// 能够触发全局懒加载的方法名
private final Set<String> lazyLoadTriggerMethods;
// 对象工厂
private final ObjectFactory objectFactory;
// 被代理类构造函数的参数列表类型
private final List<Class<?>> constructorArgTypes;
// 被代理类构造函数的参数列表
private final List<Object> constructorArgs;
// 代理类的方法被调用时都会进这个方法
@Override
public Object intercept(Object enhanced, Method method, Object[] args, MethodProxy methodProxy) throws Throwable {
final String methodName = method.getName();
try {
// 防止并发加载
synchronized (lazyLoader) {
// 调用writeReplace
if (WRITE_REPLACE_METHOD.equals(methodName)) {
// 创建原始对象
Object original;
if (constructorArgTypes.isEmpty()) {
original = objectFactory.create(type);
} else {
original = objectFactory.create(type, constructorArgTypes, constructorArgs);
}
// 将之前对象的属性拷贝到新的对象
PropertyCopier.copyBeanProperties(type, enhanced, original);
// 存在懒加载属性通过CglibSerialStateHolder封装数据
if (lazyLoader.size() > 0) {
return new CglibSerialStateHolder(original, lazyLoader.getProperties(), objectFactory, constructorArgTypes, constructorArgs);
} else {
// 直接返回原对象进行序列化
return original;
}
} else {
// 存在懒加载属性,并且不是的调用finalize方法
if (lazyLoader.size() > 0 && !FINALIZE_METHOD.equals(methodName)) {
// 设置了激进加载或者调用了能够触发全局加载的方法
if (aggressive || lazyLoadTriggerMethods.contains(methodName)) {
// 完成所有属性的懒加载
lazyLoader.loadAll();
}
// 调用了属性写方法
else if (PropertyNamer.isSetter(methodName)) {
// 清除属性的懒加载设置,后面就不需要懒加载了
final String property = PropertyNamer.methodToProperty(methodName);
lazyLoader.remove(property);
}
// 调用了属性获取接口
else if (PropertyNamer.isGetter(methodName)) {
final String property = PropertyNamer.methodToProperty(methodName);
if (lazyLoader.hasLoader(property)) {
// 如果属性没有进行懒加载则进行懒加载
lazyLoader.load(property);
}
}
}
}
}
// 触发被代理的相应方法
return methodProxy.invokeSuper(enhanced, args);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
}
// ...
}
1.5.3 parameter子包
包里面只有一个接口,主要是给sql语句中的参数赋值。实现类在scripting.defaults里面。
public interface ParameterHandler {
// 获取sql参数的实体对象
Object getParameterObject();
// sql语句中的变量赋值
void setParameters(PreparedStatement ps) throws SQLException;
}
public class DefaultParameterHandler implements ParameterHandler {
// 类型处理器注册表
private final TypeHandlerRegistry typeHandlerRegistry;
// MappedStatement包含完整的增删改查节点信息
private final MappedStatement mappedStatement;
// 参数对象
private final Object parameterObject;
// BoundSql 包含sql、参数、实参对象
private final BoundSql boundSql;
private final Configuration configuration;
@Override
public void setParameters(PreparedStatement ps) {
ErrorContext.instance().activity("setting parameters").object(mappedStatement.getParameterMap().getId());
// 获取参数列表
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
if (parameterMappings != null) {
for (int i = 0; i < parameterMappings.size(); i++) {
ParameterMapping parameterMapping = parameterMappings.get(i);
// 忽略ParameterMode.OUT
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
// 取出属性名称
String propertyName = parameterMapping.getProperty();
// 存在参数则从附加参数中获取
if (boundSql.hasAdditionalParameter(propertyName)) { // issue #448 ask first for additional params
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
}
// 参数类型是基本类型则参数对象就是参数值
else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
}
// 复杂对象则取出对象的属性值
else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
// 确认参数的处理器
TypeHandler typeHandler = parameterMapping.getTypeHandler();
JdbcType jdbcType = parameterMapping.getJdbcType();
if (value == null && jdbcType == null) {
jdbcType = configuration.getJdbcTypeForNull();
}
try {
// 通过参数类型给参数赋值
typeHandler.setParameter(ps, i + 1, value, jdbcType);
} catch (TypeException | SQLException e) {
throw new TypeException("Could not set parameters for mapping: " + parameterMapping + ". Cause: " + e, e);
}
}
}
}
}
}
1.5.4 result子包
功能主要是处理结果中的嵌套映射、根据映射关系生成结果对象、根据数据库查询的接口对对象结果赋值、将结果对象汇总List Map Cursor等。这个子包负责将结果对象汇总为List或者Map,其他的在resultSet子包里面处理
汇总为List的DefaultResultHandler、汇总为map的DefaultMapResultHandler、DefaultResultContext单独存储一条数据库结果。源码如下:
// 结果上下文 存放数据库中的一条数据
public class DefaultResultContext<T> implements ResultContext<T> {
// 结果对象
private T resultObject;
// 结果计数
private int resultCount;
// 使用完毕
private boolean stopped;
// ...
}
public class DefaultMapResultHandler<K, V> implements ResultHandler<V> {
// map形式的结果映射
private final Map<K, V> mappedResults;
// 结果对象的某个属性名
private final String mapKey;
// 对象工厂
private final ObjectFactory objectFactory;
// 对象包装工厂
private final ObjectWrapperFactory objectWrapperFactory;
// 反射工厂
private final ReflectorFactory reflectorFactory;
// 或者结果为map
@Override
public void handleResult(ResultContext<? extends V> context) {
// 获取对象的源对象
final V value = context.getResultObject();
final MetaObject mo = MetaObject.forObject(value, objectFactory, objectWrapperFactory, reflectorFactory);
// TODO is that assignment always true?
// put到map里面
final K key = (K) mo.getValue(mapKey);
mappedResults.put(key, value);
}
// ...
}
1.5.5 resultSet子包
主要进行处理结果中的嵌套映射、根据映射关系生成结果对象、根据数据库查询的接口对对象结果赋值。包里面一共有3个类ResultSetHandler接口、实现类DefaultResultSetHandler、包装器类ResultSetWrapper(包装ResultSet)。
// ResultSet处理器
public interface ResultSetHandler {
// 处理ResultSet为List
<E> List<E> handleResultSets(Statement stmt) throws SQLException;
// 处理游标ResultSet为Cursor
<E> Cursor<E> handleCursorResultSets(Statement stmt) throws SQLException;
// 存储过程的输出结果
void handleOutputParameters(CallableStatement cs) throws SQLException;
}
// 包装类提供了一些结果集的常用方法
public class ResultSetWrapper {
// 被装饰的ResultSet对象
private final ResultSet resultSet;
// 类型处理器注册表
private final TypeHandlerRegistry typeHandlerRegistry;
// 列名集合
private final List<String> columnNames = new ArrayList<>();
// 类名集合
private final List<String> classNames = new ArrayList<>();
// jdbc类型集合
private final List<JdbcType> jdbcTypes = new ArrayList<>();
// 类型与类型处理器map Map<列名, Map<java类型, 类型处理器>>
private final Map<String, Map<Class<?>, TypeHandler<?>>> typeHandlerMap = new HashMap<>();
// 所有有关系映射列名 Map<resultMap的ID, List<列名>>
private final Map<String, List<String>> mappedColumnNamesMap = new HashMap<>();
// 没有关系映射列名
private final Map<String, List<String>> unMappedColumnNamesMap = new HashMap<>();
// ...
}
1.5.6 statement子包
负责提供语句处理能力,一共有一个接口5个实现类
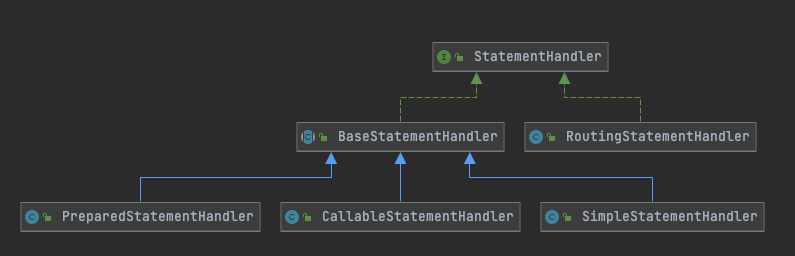
路由语句处理器是通过语句类型进行3个具体实现类的转发功能。
public class RoutingStatementHandler implements StatementHandler {
private final StatementHandler delegate;
// 根据语句类型路由到不同的语句处理实现
public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
switch (ms.getStatementType()) {
// 直接操作sql,不进行预编译,获取数据:$—Statement
case STATEMENT:
delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
// 预处理,参数,进行预编译,获取数据:#—–PreparedStatement:默认
case PREPARED:
delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
// 执行存储过程————CallableStatement
case CALLABLE:
delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
default:
throw new ExecutorException("Unknown statement type: " + ms.getStatementType());
}
}
// ... 其他方法都是进行的转发
}
3个具体的实现类逻辑都差不多,PreparedStatementHandler的源码如下:
public class PreparedStatementHandler extends BaseStatementHandler {
public PreparedStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
super(executor, mappedStatement, parameter, rowBounds, resultHandler, boundSql);
}
@Override
public int update(Statement statement) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
ps.execute();
int rows = ps.getUpdateCount();
// 数据插入后进行的KeyGenerator操作
Object parameterObject = boundSql.getParameterObject();
KeyGenerator keyGenerator = mappedStatement.getKeyGenerator();
keyGenerator.processAfter(executor, mappedStatement, ps, parameterObject);
return rows;
}
@Override
public void batch(Statement statement) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
ps.addBatch();
}
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
// jdbc声明执行
PreparedStatement ps = (PreparedStatement) statement;
ps.execute();
// 处理结果集
return resultSetHandler.handleResultSets(ps);
}
@Override
public <E> Cursor<E> queryCursor(Statement statement) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
ps.execute();
return resultSetHandler.handleCursorResultSets(ps);
}
// 实例化语句
@Override
protected Statement instantiateStatement(Connection connection) throws SQLException {
String sql = boundSql.getSql();
if (mappedStatement.getKeyGenerator() instanceof Jdbc3KeyGenerator) {
String[] keyColumnNames = mappedStatement.getKeyColumns();
if (keyColumnNames == null) {
return connection.prepareStatement(sql, PreparedStatement.RETURN_GENERATED_KEYS);
} else {
return connection.prepareStatement(sql, keyColumnNames);
}
} else if (mappedStatement.getResultSetType() == ResultSetType.DEFAULT) {
return connection.prepareStatement(sql);
} else {
return connection.prepareStatement(sql, mappedStatement.getResultSetType().getValue(), ResultSet.CONCUR_READ_ONLY);
}
}
@Override
public void parameterize(Statement statement) throws SQLException {
parameterHandler.setParameters((PreparedStatement) statement);
}
}
1.5.7 执行器核心类
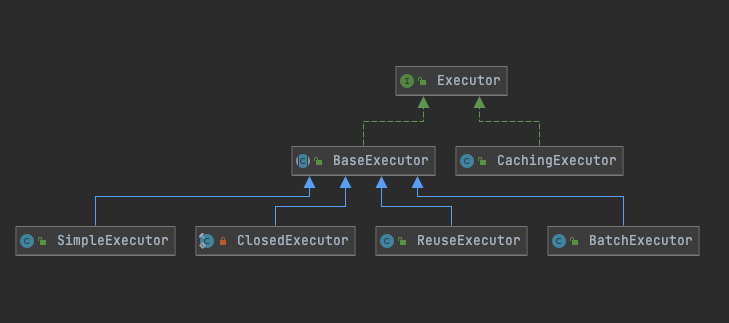
Executor执行器存在多个实现类。CachingExecutor主要的工作就是添加缓存,BaseExecutor执行器充当模版方法将通用的逻辑都放在这里执行其他的子类实现了BaseExecutor进行一些statement的创建和参数的绑定等工作。下面给出BaseExecutor的一些代码片段
// 作用于sqlSession(模版方法的作用)
// 它的子类主要的工作就是完成statement对象的创建、参数绑定等
public abstract class BaseExecutor implements Executor {
private static final Log log = LogFactory.getLog(BaseExecutor.class);
protected Transaction transaction;
protected Executor wrapper;
protected ConcurrentLinkedQueue<DeferredLoad> deferredLoads;
// 一级缓存(查询操作的结果缓存)
// 在表示会话的SqlSession对象中建立一个简单的缓存,将每次查询到的结果结果缓存起来,当下次查询的时候,
// 如果判断先前有个完全一样的查询,会直接从缓存中直接将结果取出,返回给用户,不需要再进行一次数据库查询了
protected PerpetualCache localCache;
// callable查询的输出参数缓存
protected PerpetualCache localOutputParameterCache;
protected Configuration configuration;
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
// 执行器已经关闭
throw new ExecutorException("Executor was closed.");
}
// 新的查询栈且要求重启
if (queryStack == 0 && ms.isFlushCacheRequired()) {
// 清除一级缓存
clearLocalCache();
}
List<E> list;
try {
queryStack++;
// 尝试本地缓存获取结果
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
// 本地缓存中存在结果, 如果是CALLABLE语句则绑定参数
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
}
// 缓存为空则从数据库执行sql(从数据库进行查询操作前的本地缓存处理,之后调用抽象方法doQuery)
else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
// 延迟加载处理
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
// 如果本地缓存的作用域是STATEMENT则清理缓存
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
// 更新数据库数据 insert/update/delete都调用此方法
@Override
// 更新操作的参数比较简单,查询结果的输出也是比较复杂的
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
if (closed) {
// 执行器已经关闭
throw new ExecutorException("Executor was closed.");
}
// 清理缓存
clearLocalCache();
// 返回调用子类进行操作
return doUpdate(ms, parameter);
}
// ...
}
1.6 session包
这个包里面存在SqlSessionFactoryBuilder生产了SqlSessionFactory,SqlSessionFactory生成了SqlSession以及两个接口,之后就是一些枚举类、 Configuation、SqlSessionManager(提供了复用功能)。
SqlSessionFactoryBuilder类的主要逻辑就是去解析xml报文,并创建sqlSessionFactory,源码如下:
public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) {
try {
// Xml配置构建
XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
// 将mybatis-config.xml文件解析为Document后,在解析为Configuration对象
return build(parser.parse());
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error building SqlSession.", e);
} finally {
ErrorContext.instance().reset();
try {
inputStream.close();
} catch (IOException e) {
// Intentionally ignore. Prefer previous error.
}
}
}
public SqlSessionFactory build(Configuration config) {
// 构建默认的SqlSessionFactory
return new DefaultSqlSessionFactory(config);
}
sqlSessionFactory里面主要是通过配置信息获取环境数据创建执行器之后生成了sqlSession
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
// 通过配置消息获取事务
final Environment environment = configuration.getEnvironment();
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
// 通过环境信息和事务获取执行器
final Executor executor = configuration.newExecutor(tx, execType);
// 初始化一个DefaultSqlSession
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
sqlSession里面就是去调用具体的执行器方法去执行各自的逻辑
// 执行selectList
private <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) {
try {
// 获取映射声明
MappedStatement ms = configuration.getMappedStatement(statement);
// 交给执行器去执行查询语句
return executor.query(ms, wrapCollection(parameter), rowBounds, handler);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
sqlSessionManager同时继承了sqlSession和sqlSessionFactory两个类,提供了产品复用的功能(保证了线程安全也提高了效率),能忽略生产产品的过程。
public class SqlSessionManager implements SqlSessionFactory, SqlSession {
// sqlSession工厂
private final SqlSessionFactory sqlSessionFactory;
// 代理sqlSeesion
private final SqlSession sqlSessionProxy;
// 存储被代理的sqlSession
private final ThreadLocal<SqlSession> localSqlSession = new ThreadLocal<>();
// 创建SqlSession的代理类
private SqlSessionManager(SqlSessionFactory sqlSessionFactory) {
this.sqlSessionFactory = sqlSessionFactory;
this.sqlSessionProxy = (SqlSession) Proxy.newProxyInstance(
SqlSessionFactory.class.getClassLoader(),
new Class[]{SqlSession.class},
new SqlSessionInterceptor());
}
// sqlSession拦截器
private class SqlSessionInterceptor implements InvocationHandler {
public SqlSessionInterceptor() {
// Prevent Synthetic Access
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// 获取当前线程(ThreadLocal)中的sqlSession对象
final SqlSession sqlSession = SqlSessionManager.this.localSqlSession.get();
if (sqlSession != null) {
try {
// 存在sqlSession对象则使用存在的SqlSession对象去处理
return method.invoke(sqlSession, args);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
} else {
// 不存在则从sql工厂中创建一个sqlSession对象
try (SqlSession autoSqlSession = openSession()) {
try {
// 调用方法并进行事务提交
final Object result = method.invoke(autoSqlSession, args);
autoSqlSession.commit();
return result;
} catch (Throwable t) {
// 事务回滚
autoSqlSession.rollback();
throw ExceptionUtil.unwrapThrowable(t);
}
}
}
}
}
// ...
}
之后就是一些枚举类AutoMappingBehavior自动映射行为(不映射、仅单层映射、全部映射)、AutoMappingUnknownColumnBehavior自动映射未知行为(不处理、输出告警日志、抛出异常)、ExecutorType执行器类型(简单、复用、批量)、LocalCachSpace本地缓存范围(会话、语句)、TransactionIsolationLevel事务隔离级别(无隔离、读已提交、读未提交、可重复读、可串行化)
1.7 plugin包
为了实现让其他开发者开发插件去扩展mybatis。实现mybatis的Interceptor接口即可进行相应的操作。实现原理是在执行语句的时候会把插件拦截器初始化到链条里面,初始化执行器(只有4个类会进行包装)的时候去进行包装(判断是否需要进行拦截,如果需要进行拦截则创建代理类)返回代理类,在执行代理类的时候判断是否需要进行拦截(如果需要则调用拦截器的方法进行插件的逻辑处理)。
拦截器链条代码
public class InterceptorChain {
private final List<Interceptor> interceptors = new ArrayList<>();
// 创建执行器的时候将目标类放入到所有的插件中去包装,判断是否需要拦截。如果需要拦截则创建代理类
public Object pluginAll(Object target) {
for (Interceptor interceptor : interceptors) {
target = interceptor.plugin(target);
}
return target;
}
// xml解析的时候将拦截器初始化到链条里面
public void addInterceptor(Interceptor interceptor) {
interceptors.add(interceptor);
}
public List<Interceptor> getInterceptors() {
return Collections.unmodifiableList(interceptors);
}
}
在xml解析(XMLConfigBuilder.pluginElement)的时候会调用Interceptor的addInterceptor方法去初始化拦截器
private void pluginElement(XNode parent) throws Exception {
if (parent != null) {
for (XNode child : parent.getChildren()) {
String interceptor = child.getStringAttribute("interceptor");
Properties properties = child.getChildrenAsProperties();
// 拦截器定义
Interceptor interceptorInstance = (Interceptor) resolveClass(interceptor).getDeclaredConstructor().newInstance();
// 设置拦截器属性
interceptorInstance.setProperties(properties);
// 将拦截器放入InterceptorChain
configuration.addInterceptor(interceptorInstance);
}
}
}
之后就是在生成处理器的时候去遍历拦截器链条生成代理类。如下逻辑:
// BatchExecutor类的doQuery方法
public <E> List<E> doQuery(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql)
throws SQLException {
Statement stmt = null;
try {
flushStatements();
Configuration configuration = ms.getConfiguration();
// 创建语句处理器,把处理器遍历所有的插件链判断是否需要生成代理类
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameterObject, rowBounds, resultHandler, boundSql);
Connection connection = getConnection(ms.getStatementLog());
stmt = handler.prepare(connection, transaction.getTimeout());
handler.parameterize(stmt);
// 如果是代理类则执行代理类,否则执行原本的处理器方法
return handler.query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
// 创建语句处理器
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
// 创建处理器
StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);
// 遍历所有插件判断是否生成代理类
statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);
return statementHandler;
}
// 遍历需要执行的包装方法 判断方法是否需要拦截,如果需要拦截则创建一个代理类
public static Object wrap(Object target, Interceptor interceptor) {
Map<Class<?>, Set<Method>> signatureMap = getSignatureMap(interceptor);
// 被代理对象的类型
Class<?> type = target.getClass();
// 查找父类,查看是否需要拦截
Class<?>[] interfaces = getAllInterfaces(type, signatureMap);
if (interfaces.length > 0) {
// 创建一个Plugin的代理类
return Proxy.newProxyInstance(
type.getClassLoader(),
interfaces,
new Plugin(target, interceptor, signatureMap));
}
return target;
}
再就是执行代理类的invoke方法
// 代理方法
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
// 判断方法是否需要进行拦截器方法执行
Set<Method> methods = signatureMap.get(method.getDeclaringClass());
if (methods != null && methods.contains(method)) {
return interceptor.intercept(new Invocation(target, method, args));
}
// 不需要则直接调用被代理类的方法
return method.invoke(target, args);
} catch (Exception e) {
throw ExceptionUtil.unwrapThrowable(e);
}
}
二、包结构汇总
| 包名 | 介绍 | 设计模式 |
|---|---|---|
| jdbc | 提供了sql语句生成和执行的独立功能 | |
| cache | 提供了各种缓存策略 | 包装器模式 |
| transaction | 事务的管理提供了两种方式一种是基于jdbc的一种是基于容器的 | 工厂 |
| cursor | 用游标的方式返回查询的结果数据 | |
| executor | 执行器核心类包含了自增主键的生成、懒加载(cglib的动态代理)、参数/结果/语句处理等 | 模版方法 |
| session | 主要是Sqlsesison的创建 | |
| plugin | 主要提供ParameterHandler、ResultSetHandler、StatementHandler、Executor类的插件拦截器 | 责任链 |