19_hash
一、Hash
1、均匀性:哈希函数能将任何值均匀的分布在out域上
2、范围均匀:例如将字符hash之后取模10,就可以将字符均匀的分布在0~10之间
3、hash碰撞:相同的值计算的hash值也会有很大的不同。不同的值由于范围限制也可能一样,一样的情况就是hash碰撞
3、HashMap的设计
- Hash桶: hashmap默认桶大小是16,负载因子是0.75。 当hashmap.size > 16 * 0.75时就会发生扩容。
- put操作:put时将key hash后取模16,后放入对应的位置
- 扩容:每次扩容时候重新计算所有key的hash后重新取模放入对应的位置。就算扩容时的消耗大,但是均分之后put还是O(1)
- 解决hash碰撞:发生哈希碰撞时候就利用单链表存储值,1.8之后jdk将单链表改为红黑树
二、布隆过滤器
用来优化空间的一种方式,比如100亿的黑名单数据如果存储的话需要640g空间,但是用了布隆过滤器只需要18g空间。有万分之的失误率会把白名单的数据识别为黑名单。GPT:
布隆过滤器(Bloom Filter)是一种快速、空间高效的概率数据结构,用于判断一个元素是否可能存在于一个集合中。它通过利用位数组和多个哈希函数来表示集合,并且可以在常数时间内进行查找操作。
布隆过滤器的基本原理如下:
初始化:创建一个长度为m的位数组,并将所有位初始化为0。
插入:当要将一个元素插入布隆过滤器时,使用k个不同的哈希函数对该元素进行哈希计算,得到k个哈希值。然后将位数组中对应这k个哈希值位置的位设置为1。
查询:当要查询一个元素是否存在于布隆过滤器时,同样使用k个哈希函数对该元素进行哈希计算,得到k个哈希值。然后检查位数组中这k个位置的位是否都为1,如果都为1,则表示该元素可能存在于集合中;如果有任意一个位为0,则表示该元素一定不存在于集合中。
由于布隆过滤器的位数组长度固定,因此它的空间占用相对较小。同时,查询一个元素所需的时间很短,只需要进行k次位数组访问,因此布隆过滤器的查询性能非常高。然而,布隆过滤器存在一定的误判率(False Positive),即可能把不存在的元素误认为存在于集合中,这是因为不同元素经过哈希计算后可能会映射到相同的位上。
布隆过滤器的核心思想:是将每个元素通过多个哈希函数映射到位数组的不同位置上,并将相应的位标记为1。在查找一个元素时,可以通过对该元素进行相同的哈希映射,并检查相应的位是否都为1。如果有任何一个位为0,则可以确定该元素不存在于集合中;但如果所有位都为1,则该元素可能存在于集合中,但并不能确定一定存在,因为可能存在哈希冲突。
由于布隆过滤器使用了位数组和多个哈希函数,它具有以下特点:
高效:布隆过滤器的插入和查询操作都只需要进行位操作,不需要访问真正的元素数据,使得它的性能非常高。
空间效率高:由于只使用位数组存储信息,所需的空间通常比其他数据结构(如哈希表)要小很多。
可能存在误判:布隆过滤器可能会出现误判,即判断某个元素存在于集合中,但实际上该元素并不存在。这是由于哈希冲突导致的,但可以通过适当增加位数组的大小和哈希函数的数量来降低误判率。
布隆过滤器主要应用于需要快速判断元素是否存在于大规模集合中的场景,比如网络缓存、数据字典、垃圾邮件过滤等。但它不适用于需要精确查询元素内容的场景,因为无法从布隆过滤器中获取元素的具体信息。
m、k和失误率的计算公式如下:
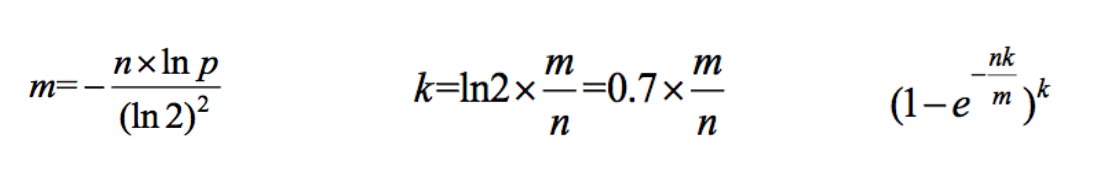
三、一致性哈希
一致性哈希是利用hash的均匀性来将数据均匀分布到不同的机器上来减少单台机器压力,一致性哈希分片数据需要注意key的选择,如果业务key本省不均匀,那么使用一致性哈希分片也是不均匀的, GPT介绍如下:
一致性哈希(Consistent Hashing)是一种用于在分布式系统中高效地进行数据分片和负载均衡的算法。它通过引入哈希环的概念,将节点和数据都映射到同一个哈希空间上。
具体实现过程如下:
将所有节点和数据根据其哈希值映射到一个固定范围的哈希环上,可以使用哈希函数来计算节点和数据的哈希值,并将哈希值映射到一个固定的环上。
当需要寻找目标数据时,先计算该数据的哈希值,然后顺时针或逆时针在环上查找最近的节点。这个节点就是负责存储该数据的节点。
如果有节点离线或新增节点加入系统,只会影响到相邻的节点,而对其他节点的影响较小。因此,整体上保持了节点的负载均衡。
一致性哈希算法的优点包括:
均衡性:在节点变动时,尽可能减少数据的迁移,保持节点的负载均衡。
扩展性:当需要增加或删除节点时,只需要迁移少量数据,对整个系统的影响较小。
缓存友好:在缓存系统中,缓存命中率高,因为数据被均匀分布在不同节点上。
一致性哈希算法在分布式存储、负载均衡、分布式缓存等场景中得到广泛应用。它能够提高系统的可扩展性和稳定性,并减少节点变动对整个系统的影响。
只是用一致性哈希分片数据的话,如果增加节点和删除节点就会有将所的数据进行迁移,工作量巨大。为了增加节点和删除节点方便,于是演化出了哈希环。
四、哈希环
将hash值0~2^64-1想象为一个环,通过将n台机器哈希后得到的值放在环上,顺时针方向获取的值就放在相临的位置上。这样扩机器和删除机器的话,就只需要将后面的节点数据迁移到新的节点即可。这样存在hash数据不均匀和加机器后数据不均匀的问题,之后通过虚拟节点技术就可以解决。
如果节点有3个,可以虚拟出3份数据,每份数据均等。然后将这3份数据都计算哈希后放到hash环上,这样就保证了3份数据的均匀性。删除和增加节点则从3份数据上均分一部分数据到增加的节点上。GPT介绍如下:
哈希环(Hash Ring)是一种数据结构,用于实现一致性哈希算法。它可以方便地将节点和数据映射到一个循环的环形空间中。
在哈希环中,每个节点通过计算其标识(如 IP 地址、节点名称等)的哈希值,并将哈希值映射到环上的一个位置。节点被均匀地分布在环上,并按顺时针顺序排列。
当需要定位数据时,将数据的标识(如键名、关键字等)计算为哈希值,并沿着环顺时针查找,找到第一个大于等于该哈希值的节点。该节点即为负责存储或处理该数据的节点。
哈希环的特点是对节点的增减具有较好的扩展性与平滑性。当节点增加或减少时,只影响相邻节点附近的数据映射,而不会影响整个环的分布情况。这样可以最小化数据迁移和分片重组的成本,同时保持较好的负载均衡。
为了进一步提高负载均衡效果,可以引入虚拟节点的概念。虚拟节点是物理节点的多个副本,可以在哈希环上占据多个位置,增加了数据的分散性和均匀性。通过适当配置虚拟节点的数量,可以更好地满足系统的负载需求。
总之,哈希环是一种用于实现一致性哈希算法的环形数据结构,通过哈希函数将节点和数据映射到环上,并提供了高效、可扩展和负载均衡的数据分布方式。
五、指定内存找到出现次数最多的数
1、题目
32位无符号整数的范围是0~4,294,967,295,现在有一个正好包含40亿个无符号整数的文件,可以使用最多1GB的内存,怎么找到出现次数最多的数?
2、思路
1、1GB内存通过计算可以得出存1千万的数据
2、40亿除以1千万则得到400
3、通过hash取值后模400则可以均分40亿的数据。相同的值hash值是一样的,则在均分的400份数据里面出现的次数相同的不会出现在其他的文件里面
4、单独找到单个文件里面出现次数最多的树后,获取400份数据最大的值就是出现次数最多的数
六、指定内存找到从未出现过的数字
1、题目
32位无符号整数的范围是0~4,294,967,295,现在有一个正好包含40亿个无符号整数的文件,所以在整个范围中必然存在没出现过的数。可以使用最多1GB的内存,怎么找到所有未出现过的数?
2、思路
1、比如利用数组10个位置,每个位置有4字节,每个字节有8bit,则表示320个bit
2、找到i的位置就是i/32就找到了数组的位置,i%32就是bit的位置
3、准备一个32位无符号整数的最大范围的数组(bit方式),遍历文件数据存在数字则把相应位置值为1
4、取出所有为0的位置就是没出现过的数
3、进阶
内存限制为 3KB,但是只用找到一个没出现过的数即可
七、超大文件找出重复URL
1、题目
有一个包含100亿个URL的大文件,假设每个URL占用64B,请找出其中所有重复的URL【补充】某搜索公司一天的用户搜索词汇是海量的(百亿数据量),请设计一种求出每天热门Top100词汇的可行办法
2、思路
1、如果可以有失误率则用布隆过滤器
2、不能有失误则用hash将文件分成多个,单个小文件找到重复url即可
八、使用最多1G内存找到大范围数据两次
1、题目
32位无符号整数的范围是0~4294967295,现在有40亿个无符号整数,可以使用最多1GB的内存,找出所有出现了两次的数。
2、思路
用2位bit代表数组出现的次数,00表示没有出现过,01表示出现了一次,10表示出现了2次,11表示2次以上
九、找到大数据量的中位数
1、题目
32位无符号整数的范围是0~4294967295,现在有40亿个无符号整数可以使用最多3K的内存,怎么找到这40亿个整数的中位数?
2、思路
1、利用hash分段计算找到范围区间
2、遍历区间里面的数字,计算获得中位数即可
十、超大原文件所有数据排序
1、题目
32位无符号整数的范围是0~4294967295,有一个10G大小的文件,每一行都装着这种类型的数字,整个文件是无序的,给你5G的内存空间,请你输出一个10G大小的文件,就是原文件所有数字排序的结果
2、思路
1、利用大根堆装5g数据,遍历大文件数据。每次入堆时判断只有最小的放在堆中
2、当堆满的时候,就将堆里面的数据从小到到写入新文件中
3、用变量记录之前大根堆最大的值,之后重新遍历入堆的数据要大于变量记录的值
4、将所有数据跑完就将所有的数据都排序了
十一、汇总
1)布隆过滤器用于集合的建立与查询,并可以节省大量空间
2)一致性哈希解决数据服务器的负载管理问题
3)利用并查集结构做岛问题的并行计算
4)哈希函数可以把数据按照种类均匀分流
5)位图解决某一范围上数字的出现情况,并可以节省大量空间
6)利用分段统计思想、并进一步节省大量空间
7)利用堆、外排序来做多个处理单元的结果合并